 So I had these 1GB+ CSV files sitting on my laptop, and I just wanted to run a couple of SQL queries on them. Simple, right? Wrong.
So I had these 1GB+ CSV files sitting on my laptop, and I just wanted to run a couple of SQL queries on them. Simple, right? Wrong.
Here were my options for something that should take 50 seconds: upload it to some hosted solution (and wait forever), throw it into a cloud bucket, set up a database, connect everything together... or use one of those browser-based CSV tools that looked like they were built in 2010 and had half the features missing.
None of these felt right for what should be a 50-second task.
The DuckDB Amsterdam Meetup
A few months back, I was at a DuckDB meetup here in Amsterdam (shoutout to the amazing crowd there!). Chris Laffra was giving this demo of pysheets.app with DuckDB-wasm, and something clicked. Wait, if DuckDB can run directly in the browser, then I could...
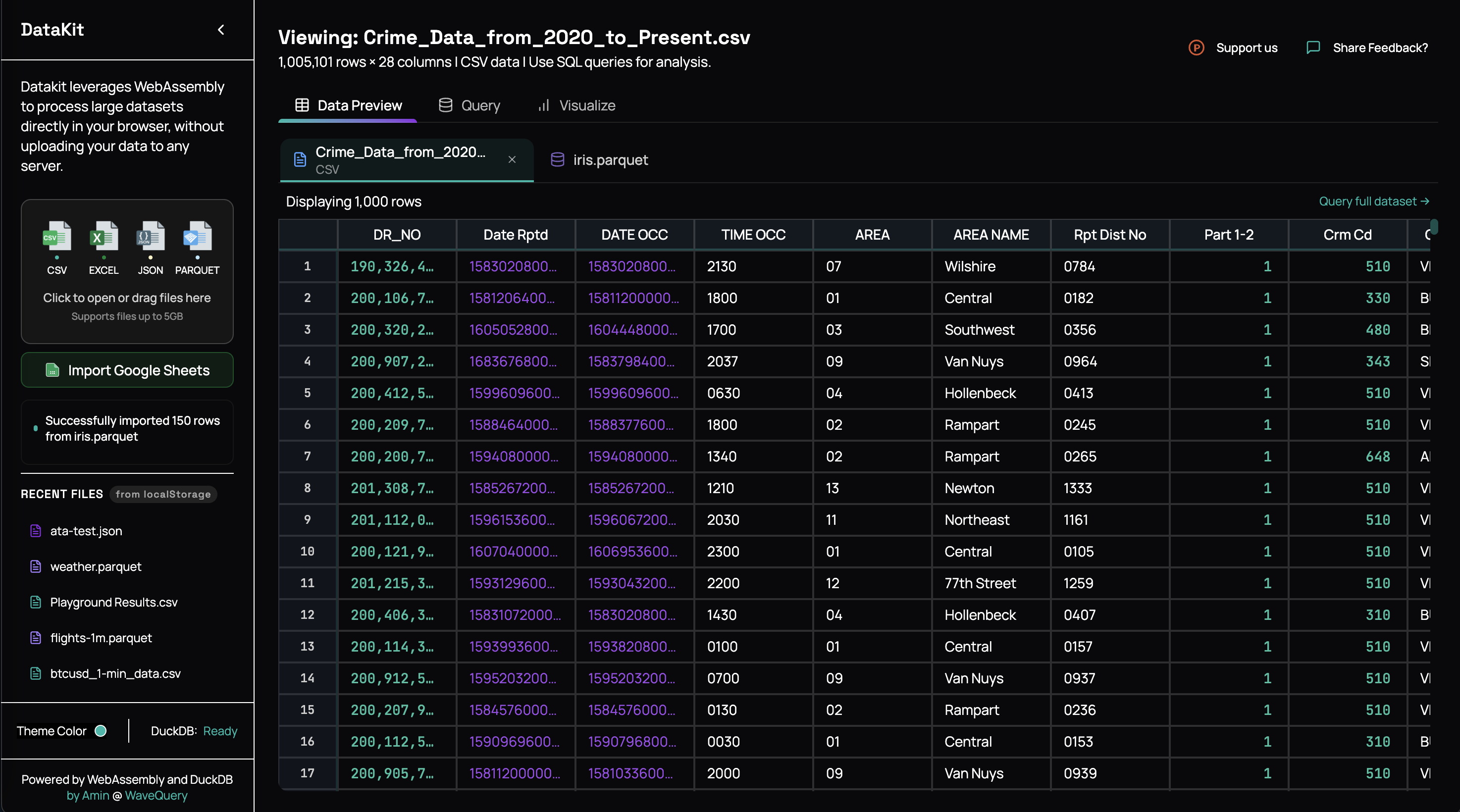
Later I realized I could build exactly what I wished existed: a tool where you drop in your CSV/JSON/EXCEL, write some SQL, and get your answers. No servers, no uploads, no BS.
Four Weeks of "This Might Actually Work"
I spent about four weeks working on this (my main stack for FE is React/TS, so I stuck with what I know). The moment I got my first 1GB file working smoothly without crashing the browser, I thought "oh, this might actually be fun."
The goal was simple: make querying local CSV/EXCEL/PARQUET/JSON files as easy as it should be. Drop file, write query, see results. That's it.
What I Built (DataKit)
DataKit ended up being this web-based tool that:
- Handles files up to 1-2GB (sometimes more, but I'm still working out some kinks with larger files)
- Runs SQL queries directly in your browser using DuckDB-wasm
- Shows you the schema automatically
- Lets you download your results
- Keeps your data completely private (it never leaves your browser)
- Some basic visualisations for aggregation queries
The whole thing runs client-side. No servers involved, which still blows some people's minds. I had a meeting where the guy couldn't believe there wasn't a server somewhere processing his data!
Why This Matters (And Why Existing Tools Frustrated Me)
I looked at what was already out there, and honestly, most tools had deal-breaking limitations. Some had no download functionality, others had interfaces that felt ancient, and many couldn't handle multi table joins or had weird UI quirks that made simple tasks take forever.
There's this comparison of existing CSV tools, and you can see how each one has these gaps that make you go "come on, this should just work."
The feedback I've gotten so far has been pretty cool. People seem surprised that the interface is intuitive and straightforward - like, it should be this simple, but apparently most tools aren't. One person said it "just makes sense," which is exactly what I was going for.
What's Next
I'm still figuring out the next steps. Maybe turning this into a proper open source project (though I need to think about that more). For now, it's just me plus a bunch of good friends throwing suggestions my way.
Thanks Tim, Luke, and so many others for all the insights! The feature requests keep coming - better query editor, sample data previews, more visualization options, clearer messaging about privacy, and fixing some design responsiveness issues. Some of these suggestions are so obvious in hindsight that they make me smile.
Try It Out
If you've ever been frustrated trying to quickly query a local file, give DataKit a shot. Drop in your file, write some SQL, see what happens. It might just work the way you expect it to.
And if you've got thoughts, suggestions, or run into issues, let me know! This is the beginning of the DataKit. I'll be writing more about the technical challenges, user feedback, and where this is heading next.
P.S. - Here's a demo video if you want to see it in action first.